Many marine species have evolved to rely primarily on sound for underwater navigation, prey detection, and communication. Marine biologists and other ocean researchers listen to the sounds generated by marine animals, for example, to detect the presence of an endangered species or to study social behavior. In recent years, increasing numbers of underwater listening and recording devices are being deployed worldwide, generating vast amounts of data that easily exceed our capacity for manual analysis. MERIDIAN is developing software packages and tools that apply state-of-the-art deep learning techniques to underwater bioacoustics. We aim to provide a library of pre-trained models that can be easily adapted or improved if necessary. We are working hard on the projects described below and will release the first outcomes in the next few months, so keep an eye on this page or subscribe to our newsletter.
Projects:
Fish detection
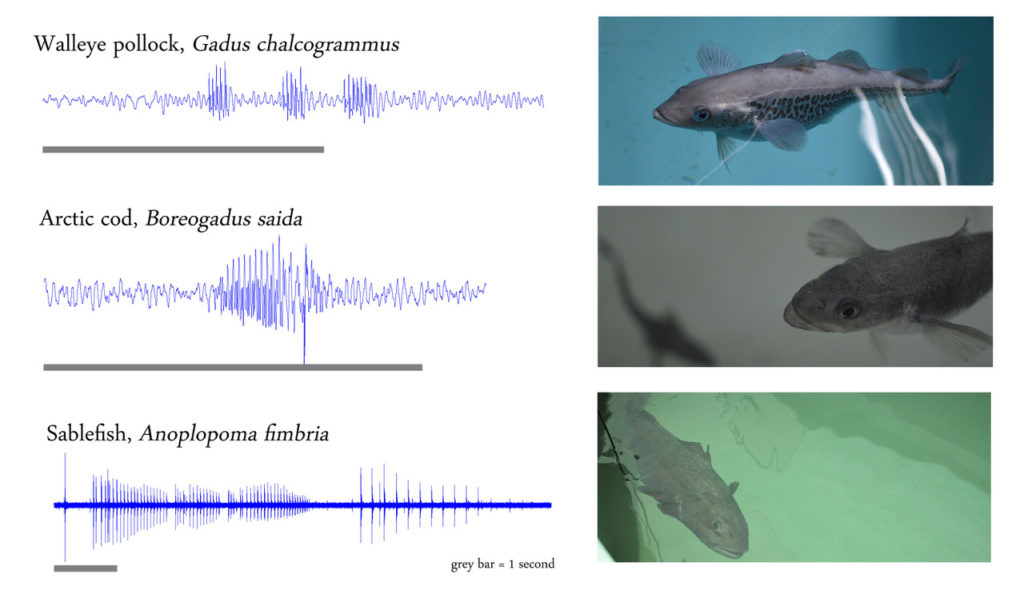
Hundreds of fish species are known to produce sounds. We are developing models using temporal convolutional networks (a neural network architecture usually applied to video data) to automatically detect fish in hydrophone data. Such models will help researchers to analyze large amounts of data that currently remains unexplored. The first species we are working with are the arctic cod and sablefish. These are a few of the species studied by Dr. Francis Juanes and Dr. Amalis Riera, biologists in the MERIDIAN team based at the University of Victoria, who closely guide us in our development efforts and work to gather the necessary data in natural and controlled environments.
Whale detection and classification
Using a combination of convolutional and recurrent neural networks, we are developing deep learning models to detect and classify several whale species, including right, sei, fin and humpback whales. We collaborate with several groups and institutions that provide us with data and their expertise. Dr. Chris Taggart and Dr. Kim Davies from the oceanography department at Dalhousie University, for example, have been studying the endangered North Atlantic right whale using underwater acoustics and a variety of other methods. They provided data collected by autonomous underwater vehicles, which we are using to develop detectors that can be evaluated. Similarly, the MERIDIAN team leader at Rimouski Dr. Yvan Simard and our collaborators at Ocean Networks Canada are also providing data sets and guidance to make sure our efforts are well aligned with the needs of the underwater acoustics community.
Interactive training app
One of the benefits of using deep learning to develop detectors and classifiers is that we can take advantage of the high plasticity of neural networks to create a model that can be tailored as needed. MERIDIAN is developing an application that will allow users to interact with a neural network as it is training, providing feedback on its performance and letting the model use the expert’s input to achieve better results. Starting with a pre-trained model, the user can apply it to a sample of a new dataset and evaluate its performance. In case the results are not satisfactory, the user can feed the model a larger amount of data and tell the model whether its outputs are correct. During this process, the application collect the user inputs to improve the model’s detection/classification abilities. This can be very useful when a pre-trained model performs very well in a given scenario (e.g.: detecting humpback whale in an area with shipping noise) but has its performance reduced in a new environment (e.g. an area with high level of seismic noise). With the help of the user, the model can adapt to the new environment more quickly. An important feature of this application is that it also works as an annotation platform, a common task in the bioacoustician’s workflow. This way a neural network can also learn by watching how the analyst does their work.
Open-source software library
Most of our tools are directed to users who don’t have advanced machine learning and software development skills: the pre-trained models and apps we are working on do not require any programming or advanced computer skills. But we also want to make sure the developers involved with underwater acoustic can take advantage of the work we do. That includes all the code we use to develop our models in an open-source library. It contains not only the neural network architectures that we find most useful for producing detectors and classifiers but also algorithms for data augmentation, utilities to deal with large datasets, several signal processing algorithms and more. Those who want to train a new model from scratch, try a variation of a network architecture or simply dig in the code base to see how things are done will be able to do so through our repositories once we release the first version of our library. Their developers will also find extensive documentation with tutorials, a testing suite, and instructions on how to contribute.
Training datasets
The success of deep learning in a variety of tasks is largely due to the amounts of data available to train these models nowadays. When it comes to underwater acoustics, however, there is still a long way to go in terms of compiling datasets useful to train detectors and classifiers, as well as properly describing and making them openly available. MERIDIAN aims to produce a series of datasets that can be used to train deep learning based detectors and classifiers for several species. These datasets can be used in conjunction with the algorithms included in our library, but the HDF5-based standard we are developing makes it easy for developers who might want to develop their own models from scratch/using other libraries. We are also developing an application assemble custom training datasets based on publicly available data and data augmentation techniques. For example, a researcher might want to use one of our pre-trained models to detect killer whales but finds the presence of dolphins in their dataset often produces false-positives. They can then use the application to add dolphin calls to a killer whale dataset and retrain the model, which might reduce the false positive rates.


